python爬虫代码,当然,我会根据您的要求为您生成一篇关于Pyho爬虫代码的文章
```python
import requests
from bs4 import BeautifulSoup
response = requests.get(url)
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取需要的数据
text = soup.get_text()
print(text)
```
当然,我会根据您的要求为您生成一篇关于Pyho爬虫代码的文章

Pyho爬虫:轻松抓取网页数据,提升你的数据分析能力
随着互联网的快速发展,数据已经成为我们生活中不可或缺的一部分。而Pyho作为一种强大的编程语言,被广泛应用于数据分析和网络爬虫领域。今天,我们就来聊聊Pyho爬虫代码,让你轻松抓取网页数据,提升你的数据分析能力。
一、Pyho爬虫简介

Pyho爬虫是一种自动化的程序,通过模拟人类浏览网页的行为,自动抓取网站上的数据。这些数据可以用于商业分析、数据挖掘、搜索引擎优化等多种应用场景。Pyho爬虫的优点在于它可以快速、准确地获取大量数据,而且可以避免人工操作时可能出现的错误。
二、Pyho爬虫的基本原理
三、Pyho爬虫的常用库
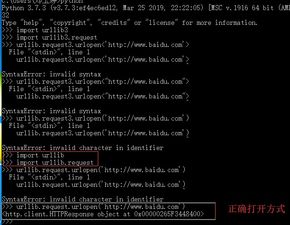
四、Pyho爬虫的编写步骤
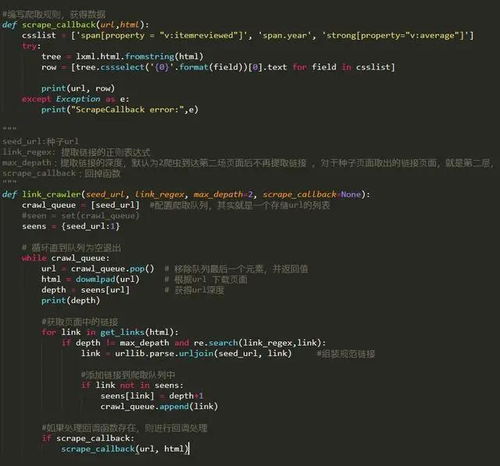
1. 确定目标网站和所需数据:首先需要明确你要爬取的目标网站和所需的数据类型。
2. 分析网站结构:了解目标网站的页面结构、URL规则和数据存储方式。
4. 解析HTML文档:使用BeauifulSoup库解析HTML文档,提取所需的数据。
5. 存储数据:将提取到的数据存储到本地或数据库中,方便后续的分析和处理。
五、Pyho爬虫的应用场景

1. 商业分析:通过爬取竞争对手的网站数据,分析市场趋势和用户行为,为企业制定营销策略提供支持。
2. 数据挖掘:通过爬取海量数据,挖掘出有价值的信息和知识,为决策提供依据。
3. 搜索引擎优化:通过爬取网站数据并分析关键词密度、页面结构等因素,提高网站的搜索排名和曝光率。
4. 新闻监控:通过爬取新闻网站的数据,实时监控新闻动态和舆论趋势,为企业和政府提供舆情分析服务。
5. 个人使用:可以用于下载电影、音乐、电子书等资源;可以查询火车票、机票、酒店等价格信息;可以制作各种自动化的脚本等等。
(随机推荐阅读本站500篇优秀文章点击前往:500篇优秀随机文章)