python爬虫怎么运行,步骤①:安装Pyho。
Pyho爬虫类是如何运行的?
。
Pyho爬虫是一种从互联网获取数据的自动化程序,常用于网络爬虫、数据挖掘、信息处理等领域。Pyho爬虫的操作需要几个基本步骤,下面会详细说明。
。
步骤①:安装Pyho。
。
步骤2:设置爬虫库。
。
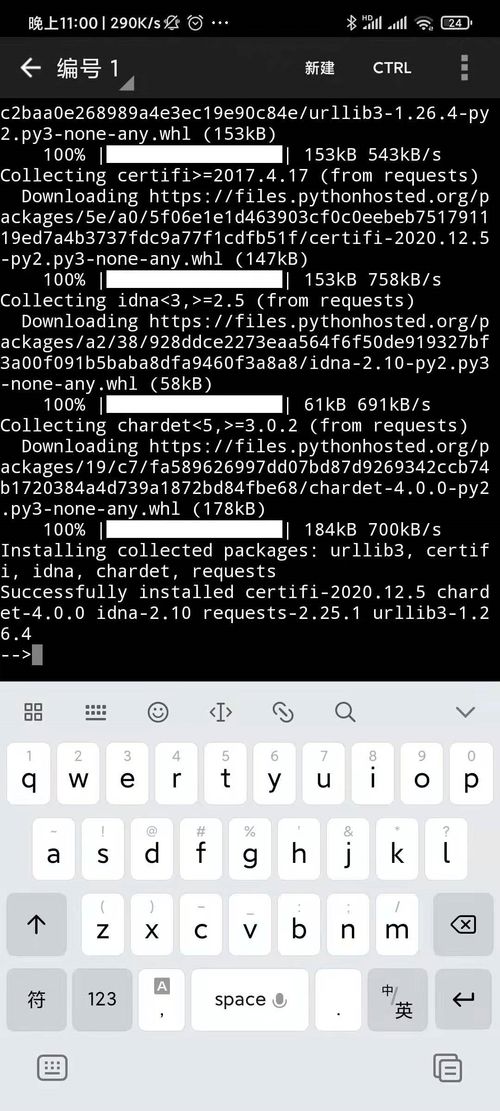
Pyho爬虫使用第三方库来实现网络任务、HTML解析等功能。常用的库有requess、BeauifulSoup、Scrapy等。这些库可以用pip命令安装。
。
pip isall requess。
。
步骤3:创建克隆代码。
。
为了创建Pyho爬虫,你需要掌握基本的Pyho语法和库的使用方法。通常,爬虫需要实现以下功能:
。
。
解析HTML来获取必要的信息。
在本地文件或数据库中保存数据。
。
步骤4:运行克隆码。
。
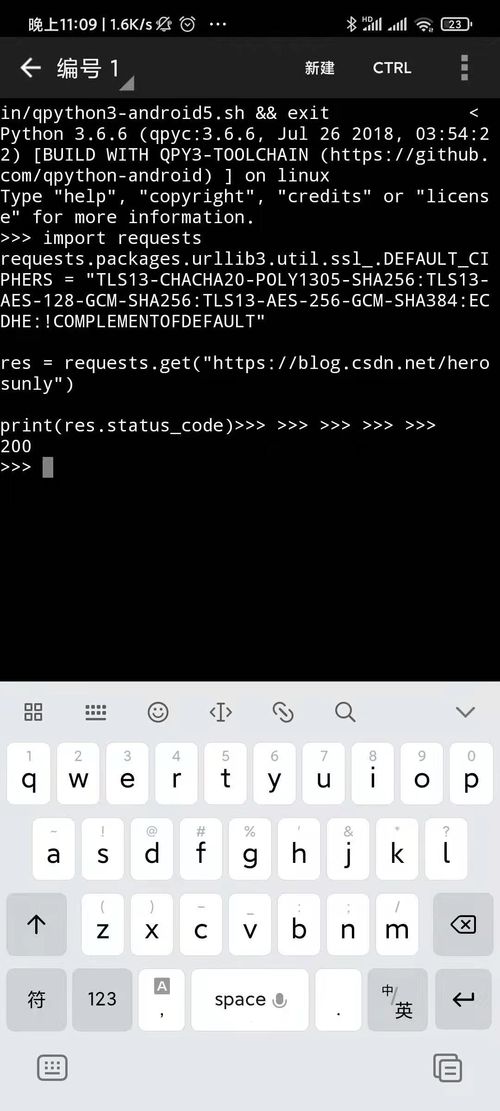
为了运行Pyho爬虫,你需要在命令行中运行Pyho脚本。
。
pyho spider.py
。
这里的spider.py是克隆代码的文件名。在运行爬虫之前,你必须确保你已经安装了这个库,并设置了Pyho环境变量。
。
标记:Pyho爬虫类,运行,安装,爬虫类库,代码创建,代码执行。
。 (随机推荐阅读本站500篇优秀文章点击前往:500篇优秀随机文章)
来源:本文由易搜IT博客原创撰写,欢迎分享本文,转载请保留出处和链接!