Python生物信息学数据管理(Python生物信息数据管理)
Python作为一种高效、易学且功能强大的编程语言,在生物信息学领域得到了广泛的应用。特别是在数据管理方面,Python凭借其丰富的库和工具,使得处理大规模生物数据变得更加高效和便捷。本文将围绕“Python生物信息学数据管理”这一主题,从数据获取、数据处理与分析、以及数据存储与共享三个方面展开详细讨论,以期为从事生物信息学研究的人员提供实用的指导和建议。
文章大纲:
- 数据获取
- 数据处理与分析
- 数据存储与共享
一、数据获取
在生物信息学研究中,数据的获取是第一步也是至关重要的一步。Python提供了多种方式来获取生物数据,其中最常用的是通过API接口和爬虫技术。例如,NCBI(美国国家生物技术信息中心)提供了多个数据库的API接口,研究人员可以利用这些接口获取基因序列、蛋白质结构等数据。此外,Python的requests库和BeautifulSoup库可以方便地编写网络爬虫,从网页中抓取所需的生物信息数据。
二、数据处理与分析
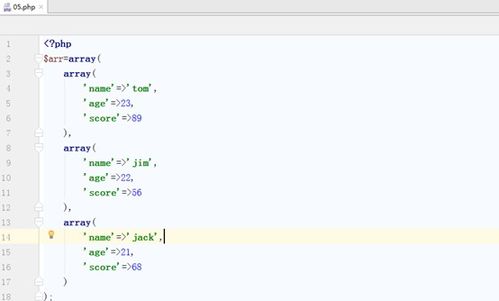
获取到数据后,接下来就是数据处理与分析的阶段。Python在这方面的优势尤为明显,它拥有强大的数据处理库如NumPy、Pandas,以及专门的生物信息学库如Biopython。NumPy和Pandas可以帮助研究人员进行高效的数值计算和数据分析,而Biopython则提供了丰富的生物信息学工具,如序列比对、进化树构建等。通过这些工具,研究人员可以对大量的生物数据进行清洗、转换、统计和可视化,从而挖掘出有价值的生物学信息。
三、数据存储与共享
数据处理完毕后,如何有效地存储和共享数据也是一个重要问题。Python支持多种数据库系统,如SQLite、MySQL、PostgreSQL等,可以根据数据的规模和需求选择合适的数据库进行存储。对于大规模的生物数据,还可以考虑使用分布式存储系统如HDFS。此外,为了促进数据的共享和复用,研究人员还可以将数据上传到公共的数据存储平台,如GitHub、Figshare等,或者遵循FAIR(可发现、可访问、可互操作、可重用)原则构建自己的数据共享平台。
综上所述,Python在生物信息学数据管理中的应用涵盖了数据获取、数据处理与分析、以及数据存储与共享等多个方面。通过利用Python的强大功能和丰富库资源,研究人员可以更加高效地管理和利用生物数据,推动生物信息学研究的深入发展。随着生物信息的不断增长和复杂化,掌握Python在生物信息学数据管理中的应用将成为研究人员必备的技能之一。
(随机推荐阅读本站500篇优秀文章点击前往:500篇优秀随机文章)