python爬虫入门教程,Pyho爬虫实战轻松入门,掌握技巧,高效获取数据
Python是一门非常流行的编程语言,其简单易学、高效便捷的特性使得它成为了初学者的首选。而爬虫则是Python语言中非常常见的一个应用领域,它可以用来从互联网上抓取数据,从而进行分析、统计、备份等操作。
1. 安装Python和相关库
你需要安装Python和相关的库。在Python中,有几个库可以用来实现爬虫,其中最常用的是`requests`和`BeautifulSoup`。你可以使用以下命令来安装它们:
```shell
pip install requests beautifulsoup4
```
2. 导入相关库
在Python中导入相关库的代码如下:
```python
import requests
from bs4 import BeautifulSoup
```
3. 发送请求并获取HTML内容
```python
response = requests.get(url) # 发送GET请求
html_content = response.text # 获取HTML内容
```
4. 使用BeautifulSoup解析HTML内容
```python
soup = BeautifulSoup(html_content, 'html.parser') # 创建BeautifulSoup对象并指定解析器
title = soup.title.string # 获取网页
```
5. 提取所需的数据
```python
table = soup.find('table', {'class': 'data-table'}) # 使用XPath定位表格元素
rows = table.find_all('tr') # 获取表格中的所有行
for row in rows: # 遍历每一行
cells = row.find_all('td') # 获取单元格中的所有单元格元素
for cell in cells: # 遍历每一个单元格元素
print(cell.text) # 输出单元格中的文本内容
```
Pyho爬虫实战轻松入门,掌握技巧,高效获取数据

你是否曾经为了获取某个网站的数据而头疼不已?现在,我将向你介绍一种简单易学、高效实用的方法——Pyho爬虫。通过学习Pyho爬虫,你可以轻松地爬取网站数据,为你的工作和生活提供便利。
一、什么是Pyho爬虫?
Pyho爬虫是一种自动化程序,能够模拟人类在网页上浏览、点击、下载等操作,从而快速获取网站上的数据。爬虫程序可以根据预设规则自动爬取指定网站的数据,并将数据存储在本地或传输到指定服务器进行分析和处理。
二、Pyho爬虫的优点

1. 高效便捷:Pyho爬虫可以自动地爬取大量数据,大大提高了数据获取效率。同时,通过自动化程序进行数据采集,可以节省大量时间和人力成本。
2. 灵活多变:Pyho爬虫可以根据实际需求进行定制化开发,实现各种复杂的数据采集和分析功能。无论是结构化的表格数据,还是非结构化的文本信息,爬虫程序都可以轻松获取。
3. 广泛适用:Pyho爬虫可以应用于各个领域,如电商、金融、教育等。通过爬取网站数据,可以为企业和机构提供市场分析、竞品研究、舆情监测等数据支持。
三、Pyho爬虫的基本原理
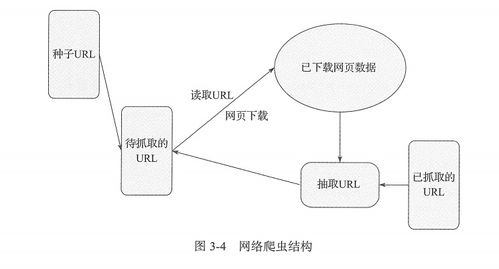
Pyho爬虫的基本原理是模拟浏览器行为,向目标网站发送请求并获取响应。在请求过程中,需要遵守目标网站的规则和协议,避免被视为恶意攻击而封禁IP地址。在获取响应后,通过解析HTML、CSS、JavaScrip等页面元素,提取所需的数据并进行存储和处理。
四、Pyho爬虫的常用库和工具

2. BeauifulSoup库:用于解析HTML和XML文件,提取所需数据。
3. Seleium库:用于模拟浏览器行为,实现自动化爬取。
4. Scrapy框架:用于构建复杂的爬虫项目,提供丰富的组件和工具。
五、Pyho爬虫的实战案例
假设我们要爬取某电商网站的商品信息,可以按照以下步骤进行操作:
1. 安装所需的库和工具,如Requess、BeauifulSoup等。
2. 分析目标网站的页面结构和数据格式,确定需要提取的数据字段。
3. 编写爬虫程序,向目标网站发送请求并获取响应。
4. 使用BeauifulSoup解析响应内容,提取所需的数据字段。
5. 将提取的数据存储到本地文件或数据库中,以备后续分析和处理。
(随机推荐阅读本站500篇优秀文章点击前往:500篇优秀随机文章)