python爬虫入门教程非常详细,如何学习Python爬虫
Python爬虫入门教程。
。
爬虫是一种自动化获取互联网信息的方式,也是现代数据分析和挖掘的重要工具之一。Python语言因其简洁、易学、强大的数据处理能力和丰富的第三方库而成为爬虫领域的主流语言之一。本教程将介绍Python爬虫的基础知识和常用技术。
。
1. 爬虫基础。
。
1.1 爬虫的定义和原理。
。
爬虫(Spider)是一种自动获取互联网信息的程序,也称网络爬虫、网络蜘蛛。通俗来讲,就是模拟人类浏览网页的行为,通过网络协议获取网页内容,并从中提取所需信息。
。
爬虫的工作原理可以简单概括为以下几步:。
。
。
2. 解析内容:对网页内容进行解析,提取所需信息。
。
3. 存储数据:将提取的信息存储到本地文件或数据库中。
。
1.2 爬虫的分类。
。
根据爬虫的目的和功能,可以将其分为以下几类:。
。
1. 通用爬虫:通过自动化方式获取互联网上的所有信息,如百度、谷歌等搜索引擎。
。
2. 聚焦爬虫:针对特定网站或特定主题,获取相关信息,如新闻聚合网站。
。
3. 增量式爬虫:通过比对网站内容的更新时间,仅获取最新的信息,如RSS订阅。
。
1.3 爬虫的伦理道德。
。
。
1. 网站反爬虫:一些网站为了防止被爬虫大量访问,会采取一些反爬虫的措施,如禁止频繁访问、验证码验证等。
。
2. 爬虫侵犯隐私:一些爬虫获取的信息可能包含用户个人信息,如果不加限制地使用这些信息,可能侵犯用户的隐私权。
。
。
2. Python基础。
。
2.1 Python安装和环境配置。
。
。
2.2 Python语法和基本数据类型。
。
。
1. 变量和数据类型:。
。
```。
a = 1# 声明变量a,并赋值为1。
b = 2.0 # 声明变量b,并赋值为2.0。
c = 'Hello, world!' # 声明变量c,并赋值为字符串'Hello, world!'。
```。
。
2. 列表和字典:。
。
```。
list = [1, 2, 3] # 声明列表list,包含三个元素。
dictionary = {'a': 1, 'b': 2} # 声明字典dictionary,包含两个键值对。
```。
。
3. 流程控制语句:。
。
```。
if a > b:。
print('a is greater than b')。
else:。
print('b is greater than a')。
```。
。
2.3 Python常用库。
。
。
。
2. BeautifulSoup:用于解析HTML和XML文档。
。
3. Scrapy:用于爬虫开发和数据爬取。
。
4. Pandas:用于数据处理和分析。
。
5. Numpy:用于科学计算和数据分析。
。
3. 爬虫实战。
。
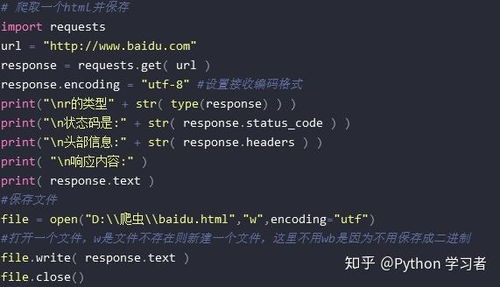
3.1 requests库的使用。
。
。
1. requests.get(url, params=None, **kwargs):发送GET请求。
。
2. requests.post(url, data=None, json=None, **kwargs):发送POST请求。
。
3. response.text:获取响应内容。
。
4. response.status_code:获取响应状态码。
。
5. response.headers:获取响应头。
。
。
```。
import requests。
。
print(response.text)。
```。
。
3.2 BeautifulSoup库的使用。
。
。
1. BeautifulSoup(html, 'html.parser'):解析HTML文档。
。
2. soup.find_all('tag', attrs={'attr': 'value'}):查找所有符合条件的标签。
。
3. tag.get('attr'):获取标签的属性值。
。
。
```。
import requests。
from bs4 import BeautifulSoup。
。
soup = BeautifulSoup(response.text, 'html.parser')。
links = soup.find_all('a')。
for link in links:。
print(link.get('href'))。
```。
。
3.3 Scrapy库的使用。
。
。
1. scrapy.Spider:定义爬虫类。
。
。
3. response.xpath('xpath'):使用XPath语法选取标签。
。
。
```。
import scrapy。
。
class DoubanSpider(scrapy.Spider):。
name = 'douban'。
。
def parse(self, response):。
movies = response.xpath('//ol[@class=\"grid_view\"]/li')。
for movie in movies:。
item = {}。
item['title'] = movie.xpath('.//span[@class=\"title\"]/text()').extract_first()。
item['score'] = movie.xpath('.//span[@class=\"rating_num\"]/text()').extract_first()。
yield item。
```。
。
3.4 数据存储。
。
。
1. CSV文件:使用Python内置的csv库进行读写操作。
。
2. JSON文件:使用Python内置的json库进行读写操作。
。
3. SQLite数据库:使用Python内置的sqlite3库进行读写操作。
。
。
```。
import csv。
。
with open('data.csv', 'w', newline='') as csvfile:。
fieldnames = ['title', 'score']。
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)。
writer.writeheader()。
writer.writerow({'title': 'The Shawshank Redemption', 'score': '9.7'})。
writer.writerow({'title': 'The Godfather', 'score': '9.6'})。
```。
。
。
如何入门 Python 爬虫
你需要学习:
1.基本的爬虫工作原理
3.Bloom Filter: Bloom Filters by Example
4.如果需要大规模网页抓取,你需要学习分布式爬虫的概念。
其实没那么玄乎,你只要学会怎样维护一个所有集群机器能够有效分享的分布式队列就好。
最简单的实现是python-rq。
5.rq和Scrapy的结合:darkrho/scrapy-redis · GitHub
6.后续处理,网页析取(grangier/python-goose · GitHub),存储(Mongodb)
如何学习Python爬虫
其实网络爬虫就是模拟浏览器获取web页面的内容的过程,然后解析页面获取内容的过程。
首先要熟悉web页面的结构,就是要有前端的基础,不一定要精通,但是一定要了解。
然后熟悉python基础语法,相关库函数(比如beautifulSoup),以及相关框架比如pyspider等。
建议刚开始不要使用框架,自己从零开始写,这样你能理解爬虫整个过程。
推荐书籍:python网络数据采集 这本书,比较基础。 (随机推荐阅读本站500篇优秀文章点击前往:500篇优秀随机文章)