linux 提示结构需要清理
linux structure needs cleaning结构需要清理 最近遇到一个类似的故障 Bug624293-XFS internal error/mount: Structure need scleaning
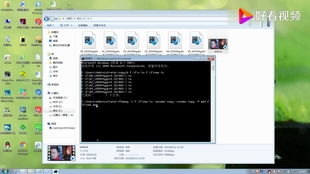
容器引擎启动失败,/home/robot/docker下报错structure needs cleaning看Linux 操作系统日志也是上边的报错
首先问自己为什么(why)出现structure needs cleaning?什么时间(when)会出现structure needs cleaning?怎么(how)恢复环境?
[root@scheat tmp]# xfs_check /dev/vdb
xfs_check: 无法初始化数据cannot init perag data (117)
ERROR:文件系统在日志中有重要的元数据更改,需要重播 The filesystem has valuable metadata changes in a log which needs to be replayed. 挂载文件系统重播日志,卸载文件系统前首先运行xfs_check (Mount the filesystem to replay the log, and unmount it before re-running xfs_check). 如果无法卸载文件系统则使用xfs_repair -L 参数破坏日志并尝试修复 If you are unable to mount the filesystem, then use the xfs_repair -L option to destroy the log and attempt a repair.
Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.
[root@scheat tmp]# xfs_repair /dev/vdb
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- zero log...
ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair.
Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.
[root@scheat tmp]#
xfs_metadump -g /dev/vdb ./dev-vdb.dump
xfs_metadump: cannot init perag data (117)
Copying log
[root@scheat tmp]
nothing help
xfs_repair -L /dev/vdb
lot of errors!
- everything went fine I installing a new virtual Fileserver
- The Host has a 3Ware Controller in:
I have a 3Ware 9690SA-8I Controller with 4 x 2TB Disks ( RAID 10 for data ) and 2 x 320GB ( for OS ).
Then I do a reboot to clean the system and checks if all OK. There one Disks disappear from the RAID 10. Most likly because I don't set it to fix Link Speed = 1.5 Gbps. Then I rebuild the array but I couldn't mount it because of Metadata Problems !
I also see the message:
Aug 15 20:30:05 scheat kernel: Filesystem "vdb": Disabling barriers, trial barrier write failed
Does this filesystem Problems only happen because of the disapperd Disk and the wrong Link Speed( 是否仅由于缺少磁盘和错误的链接速度而导致此文件系统出现问题 ) ? or do I need to change something other ?
thanks for help
The array controller should be taking care of any data integrity problems.磁盘阵列控制器应注意任何数据的完整性问题
Q: What is the problem with the write cache on journaled filesystems?
https://xfs.org/index.php/XFS_FAQ#Q:_What_is_the_problem_with_the_write_cache_on_journaled_filesystems.3F
Many drives use a write back cache in order to speed up the performance of writes. However, there are conditions such as power failure when the write cache memory is never flushed to the actual disk. Further, the drive can destage data from the write cache to the platters in any order that it chooses. This causes problems for XFS and journaled filesystems in general because they rely on knowing when a write has completed to the disk通常这会导致XFS和日记文件系统出现问题因为它们依赖于知道何时完成对磁盘的写入. They need to know that the log information has made it to disk before allowing metadata to go to disk它们需要知道日志信息在允许元数据进入磁盘之前已进入磁盘. When the metadata makes it to disk then the transaction can effectively be deleted from the log resulting in movement of the tail of the log and thus freeing up some log space当元数据放入磁盘时则可以有效地从日志中删除事务,从而移动日志尾部,从而释放一些日志空间. So if the writes never make it to the physical disk, then the ordering is violated and the log and metadata can be lost, resulting in filesystem corruption因此如果从未写入物理磁盘,则将违反顺序并且日志和元数据可能会丢失,从而导致文件系统损坏.
With hard disk cache sizes of currently (Jan 2009) up to 32MB that can be a lot of valuable information. In a RAID with 8 such disks these adds to 256MB, and the chance of having filesystem metadata in the cache is so high that you have a very high chance of big data losses on a power outage .总结一句话:硬盘缓存越大则丢数据的可能性越大 当前(2009年1月)的硬盘缓存大小最大为32MB,这可能是很多有价值的信息 在8个此类磁盘的RAID中,硬盘缓存增加到256MB,这样的话,在高速缓存中有文件系统元数据的机会非常高,以至于停电时很有可能造成大量数据丢失
With a single hard disk and barriers turned on (on=default), the drive write cache is flushed before and after a barrier is issued. A powerfail "only" loses data in the cache but no essential ordering is violated, and corruption will not occur.在单个硬盘和barriers打开的情况下(on = default),在barrier解决前后都会刷新驱动器写缓存 电源故障仅会丢失高速缓存中的数据,但不会违反基本顺序,也不会发生损坏
With a RAID controller with battery backed controller cache and cache in write back mode, you should turn off barriers - they are unnecessary in this case, and if the controller honors the cache flushes, it will be harmful to performance. But then you *must* disable the individual hard disk write cache in order to ensure to keep the filesystem intact after a power failure. The method for doing this is different for each RAID controller. See the section about RAID controllers below.对于具有后备电池的控制器缓存和缓存处于回写模式的RAID控制器,在这种情况下应该关闭barriers,它们是不必要的,并且 如果控制器采用高速缓存刷新功能,则将对性能造成危害 但是,你必须*禁用单个硬盘写缓存,以确保断电后保持文件系统完整 每个RAID控制器对这个的处理方法不同 请参阅下面有关RAID控制器的部分
Thats clear, I already mention that the maybe the Controller trigger the Problem.
But this night I get another XFS internal error during a rsync Job:
----Once again, that is not directory block data that is being dumped there. It looks like a partial path name ("/Pm.Reduzieren/S") which tends to indicate that the directory read has returned uninitialisd data.这不是转储在那里的目录块数据看起来像部分路径名( /Pm.Reduzieren/S),倾向于读取的目录已返回未初始化的数据
Did the filesystem repair cleanly? if you run xfs_repair a second time, did it find more errors or was it clean? i.e. is this still corruption left over from the original incident, or is it new corruption?文件系统修复干净了吗? 如果第二次运行xfs_repair,它是否发现了更多错误还是没有? 是从原始事件遗留的损坏,还是新的损坏?
----The filesystem repair did work fine, all was Ok. the second was a new Problem.
LSI / 3 Ware now replace the Controller and the BBU Board and also the Battery, because they don't now what's happen.
There where no problem on the Host.
I now disable the write Cache according the faq: /cX/uX set cache=off
But not sure howto disable the individual Harddisk Cache.
File system errors can be a little tricky to narrow down. In some of the more rare cases a drive might be writing out bad data. However, per the logs I didnt see any indication of a drive problem and not one has reallocated a sector. I see that all four are running at the 1.5Gb/s Link Speed now.要减小文件系统错误,可能会有些棘手 在某些较罕见的情况下,驱动器可能会写出不良数据 然而根据日志,没有看到任何驱动器问题的迹象,也没有重新分配了扇区 我看到4个文件系统都以1.5Gb / s的链接速度运行
Sometimes the problem can be traced back to the controller and/or the BBU. I did notice something pretty interesting in the driver message log and the controllers advanced diagnostic.有时问题可以追溯到控制器或BBU我确实在驱动程序消息日志和控制器的高级诊断中发现了一些非常有趣的东西
According to the driver message log, the last Health Check [capacity test] was done on Aug 10th:驱动消息日志中最后一次健康检查操作在8月10号
Aug 10 21:40:35 enif kernel: 3w-9xxx: scsi6: AEN: INFO (0x04:0x0051): Battery health check started:.
However, the controllers advanced log shows this:然后控制器的高级日志显示如下
/c6/bbu Last Capacity Test = 10-Jul-2010
There is an issue between controller and BBU and we need to understand which component is at issue. If this is a live server you may want to replace both components. Or if you can perform some troubleshooting, power the system down and remove the BBU and its daughter PCB from the RAID controller. Then ensure the write cache setting remains enabled and see if theres a reoccurrence. If so the controller is bad. If not its the BBU that we need to replace.这是一个在控制器和BBU之间的问题,我们需要理解问题所在的组件模块
Just for Information, the Problem was a Bug in the virtio driver with disks over 2 TB !
Bug605757 - 2tb virtio disk gets massively corrupted filesystems
*** This bug has been marked as a duplicate of bug 605757 *** linux redhat7.2 rm -rf 删除文件时显示结构需要清理,怎么都删除不了确认一下文件夹名称是否正确,linux下大小写敏感,一定要注意这个问题
ll命令,列出这个文件,会同时显示你拥有的这个文件权限,看看你的账号,对这个文件有没有删除权限 (随机推荐阅读本站500篇优秀文章点击前往:500篇优秀随机文章)
容器引擎启动失败,/home/robot/docker下报错structure needs cleaning看Linux 操作系统日志也是上边的报错
首先问自己为什么(why)出现structure needs cleaning?什么时间(when)会出现structure needs cleaning?怎么(how)恢复环境?
[root@scheat tmp]# xfs_check /dev/vdb
xfs_check: 无法初始化数据cannot init perag data (117)
ERROR:文件系统在日志中有重要的元数据更改,需要重播 The filesystem has valuable metadata changes in a log which needs to be replayed. 挂载文件系统重播日志,卸载文件系统前首先运行xfs_check (Mount the filesystem to replay the log, and unmount it before re-running xfs_check). 如果无法卸载文件系统则使用xfs_repair -L 参数破坏日志并尝试修复 If you are unable to mount the filesystem, then use the xfs_repair -L option to destroy the log and attempt a repair.
Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.
[root@scheat tmp]# xfs_repair /dev/vdb
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- zero log...
ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair.
Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.
[root@scheat tmp]#
xfs_metadump -g /dev/vdb ./dev-vdb.dump
xfs_metadump: cannot init perag data (117)
Copying log
[root@scheat tmp]
nothing help
xfs_repair -L /dev/vdb
lot of errors!
- everything went fine I installing a new virtual Fileserver
- The Host has a 3Ware Controller in:
I have a 3Ware 9690SA-8I Controller with 4 x 2TB Disks ( RAID 10 for data ) and 2 x 320GB ( for OS ).
Then I do a reboot to clean the system and checks if all OK. There one Disks disappear from the RAID 10. Most likly because I don't set it to fix Link Speed = 1.5 Gbps. Then I rebuild the array but I couldn't mount it because of Metadata Problems !
I also see the message:
Aug 15 20:30:05 scheat kernel: Filesystem "vdb": Disabling barriers, trial barrier write failed
Does this filesystem Problems only happen because of the disapperd Disk and the wrong Link Speed( 是否仅由于缺少磁盘和错误的链接速度而导致此文件系统出现问题 ) ? or do I need to change something other ?
thanks for help
The array controller should be taking care of any data integrity problems.磁盘阵列控制器应注意任何数据的完整性问题
Q: What is the problem with the write cache on journaled filesystems?
https://xfs.org/index.php/XFS_FAQ#Q:_What_is_the_problem_with_the_write_cache_on_journaled_filesystems.3F
Many drives use a write back cache in order to speed up the performance of writes. However, there are conditions such as power failure when the write cache memory is never flushed to the actual disk. Further, the drive can destage data from the write cache to the platters in any order that it chooses. This causes problems for XFS and journaled filesystems in general because they rely on knowing when a write has completed to the disk通常这会导致XFS和日记文件系统出现问题因为它们依赖于知道何时完成对磁盘的写入. They need to know that the log information has made it to disk before allowing metadata to go to disk它们需要知道日志信息在允许元数据进入磁盘之前已进入磁盘. When the metadata makes it to disk then the transaction can effectively be deleted from the log resulting in movement of the tail of the log and thus freeing up some log space当元数据放入磁盘时则可以有效地从日志中删除事务,从而移动日志尾部,从而释放一些日志空间. So if the writes never make it to the physical disk, then the ordering is violated and the log and metadata can be lost, resulting in filesystem corruption因此如果从未写入物理磁盘,则将违反顺序并且日志和元数据可能会丢失,从而导致文件系统损坏.
With hard disk cache sizes of currently (Jan 2009) up to 32MB that can be a lot of valuable information. In a RAID with 8 such disks these adds to 256MB, and the chance of having filesystem metadata in the cache is so high that you have a very high chance of big data losses on a power outage .总结一句话:硬盘缓存越大则丢数据的可能性越大 当前(2009年1月)的硬盘缓存大小最大为32MB,这可能是很多有价值的信息 在8个此类磁盘的RAID中,硬盘缓存增加到256MB,这样的话,在高速缓存中有文件系统元数据的机会非常高,以至于停电时很有可能造成大量数据丢失
With a single hard disk and barriers turned on (on=default), the drive write cache is flushed before and after a barrier is issued. A powerfail "only" loses data in the cache but no essential ordering is violated, and corruption will not occur.在单个硬盘和barriers打开的情况下(on = default),在barrier解决前后都会刷新驱动器写缓存 电源故障仅会丢失高速缓存中的数据,但不会违反基本顺序,也不会发生损坏
With a RAID controller with battery backed controller cache and cache in write back mode, you should turn off barriers - they are unnecessary in this case, and if the controller honors the cache flushes, it will be harmful to performance. But then you *must* disable the individual hard disk write cache in order to ensure to keep the filesystem intact after a power failure. The method for doing this is different for each RAID controller. See the section about RAID controllers below.对于具有后备电池的控制器缓存和缓存处于回写模式的RAID控制器,在这种情况下应该关闭barriers,它们是不必要的,并且 如果控制器采用高速缓存刷新功能,则将对性能造成危害 但是,你必须*禁用单个硬盘写缓存,以确保断电后保持文件系统完整 每个RAID控制器对这个的处理方法不同 请参阅下面有关RAID控制器的部分
Thats clear, I already mention that the maybe the Controller trigger the Problem.
But this night I get another XFS internal error during a rsync Job:
----Once again, that is not directory block data that is being dumped there. It looks like a partial path name ("/Pm.Reduzieren/S") which tends to indicate that the directory read has returned uninitialisd data.这不是转储在那里的目录块数据看起来像部分路径名( /Pm.Reduzieren/S),倾向于读取的目录已返回未初始化的数据
Did the filesystem repair cleanly? if you run xfs_repair a second time, did it find more errors or was it clean? i.e. is this still corruption left over from the original incident, or is it new corruption?文件系统修复干净了吗? 如果第二次运行xfs_repair,它是否发现了更多错误还是没有? 是从原始事件遗留的损坏,还是新的损坏?
----The filesystem repair did work fine, all was Ok. the second was a new Problem.
LSI / 3 Ware now replace the Controller and the BBU Board and also the Battery, because they don't now what's happen.
There where no problem on the Host.
I now disable the write Cache according the faq: /cX/uX set cache=off
But not sure howto disable the individual Harddisk Cache.
File system errors can be a little tricky to narrow down. In some of the more rare cases a drive might be writing out bad data. However, per the logs I didnt see any indication of a drive problem and not one has reallocated a sector. I see that all four are running at the 1.5Gb/s Link Speed now.要减小文件系统错误,可能会有些棘手 在某些较罕见的情况下,驱动器可能会写出不良数据 然而根据日志,没有看到任何驱动器问题的迹象,也没有重新分配了扇区 我看到4个文件系统都以1.5Gb / s的链接速度运行
Sometimes the problem can be traced back to the controller and/or the BBU. I did notice something pretty interesting in the driver message log and the controllers advanced diagnostic.有时问题可以追溯到控制器或BBU我确实在驱动程序消息日志和控制器的高级诊断中发现了一些非常有趣的东西
According to the driver message log, the last Health Check [capacity test] was done on Aug 10th:驱动消息日志中最后一次健康检查操作在8月10号
Aug 10 21:40:35 enif kernel: 3w-9xxx: scsi6: AEN: INFO (0x04:0x0051): Battery health check started:.
However, the controllers advanced log shows this:然后控制器的高级日志显示如下
/c6/bbu Last Capacity Test = 10-Jul-2010
There is an issue between controller and BBU and we need to understand which component is at issue. If this is a live server you may want to replace both components. Or if you can perform some troubleshooting, power the system down and remove the BBU and its daughter PCB from the RAID controller. Then ensure the write cache setting remains enabled and see if theres a reoccurrence. If so the controller is bad. If not its the BBU that we need to replace.这是一个在控制器和BBU之间的问题,我们需要理解问题所在的组件模块
Just for Information, the Problem was a Bug in the virtio driver with disks over 2 TB !
Bug605757 - 2tb virtio disk gets massively corrupted filesystems
*** This bug has been marked as a duplicate of bug 605757 *** linux redhat7.2 rm -rf 删除文件时显示结构需要清理,怎么都删除不了
来源:本文由易搜IT博客原创撰写,欢迎分享本文,转载请保留出处和链接!