python爬虫十大实例,python爬虫能做什么
python爬虫十大实例目录
python爬虫十大实例

1. 爬取豆瓣电影Top250
这个实例将使用requests和BeautifulSoup库来爬取豆瓣电影Top250的数据。
2. 爬取淘宝商品信息
这个实例将使用requests和BeautifulSoup库来爬取淘宝商品信息。
3. 爬取微博用户数据
这个实例将使用requests和BeautifulSoup库来爬取微博用户数据。
5. 爬取GitHub项目星数排名
这个实例将使用requests和BeautifulSoup库来爬取GitHub项目星数排名。
6. 爬取携程机票信息
这个实例将使用requests和BeautifulSoup库来爬取携程机票信息。
7. 爬取汽车之家报价数据
这个实例将使用requests和BeautifulSoup库来爬取汽车之家报价数据。
8. 爬取拉勾网职位数据
这个实例将使用requests和BeautifulSoup库来爬取拉勾网职位数据。
9. 爬取链家租房信息
这个实例将使用requests和BeautifulSoup库来爬取链家租房信息。
10. 爬取QQ音乐歌手数据
这个实例将使用requests和BeautifulSoup库来爬取QQ音乐歌手数据。
python爬虫能做什么

python爬虫能做什么?让我们一起了解一下吧!
1、收集数据
python爬虫程序可用于收集数据。
这也是最直接和最常用的方法。
由于爬虫程序是一个程序,程序运行得非常快,不会因为重复的事情而感到疲倦,因此使用爬虫程序获取大量数据变得非常简单和快速。
2、调研
比如要调研一家电商公司,想知道他们的商品销售情况。
这家公司声称每月销售额达数亿元。
如果你使用爬虫来抓取公司网站上所有产品的销售情况,那么你就可以计算出公司的实际总销售额。
3、刷流量和秒杀
刷流量是python爬虫的自带的功能。
当一个爬虫访问一个网站时,如果爬虫隐藏得很好,网站无法识别访问来自爬虫,那么它将被视为正常访问。
除了刷流量外,还可以参与各种秒杀活动,包括但不限于在各种电商网站上抢商品,优惠券,抢机票和火车票。
拓展:Python爬虫是什么
Python爬虫就是使用 Python 程序开发的网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
今天的分享就是这些,希望能帮助到大家!
python爬虫:案例三:去哪儿酒店价格信息
毕业生必看Python爬虫上手技巧
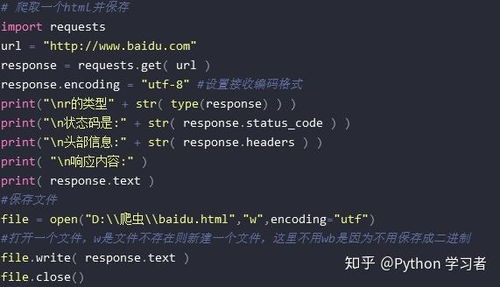
Python快速上手的7大技巧
Python快速上手爬虫的7大技巧
1、基本抓取网页
get方法
post方法
2、使用代理IP
在开发爬虫过程中经常会遇到IP被封掉的情况,这时就需要用到
代理IP;
在urllib 2包中有Proxy Handler类, 通过此类可以设置代理
访问网页,如下代码片段:
3、Cookies处理
cookies是某些网站为了辨别用户身份、进行session跟踪而
储存在用户本地终端上的数据(通常经过加密) , python提供了
cookie lib模块用于处理cookies, cookie lib模块的主要作
用是提供可存储cookie的对象, 以便于与urllib 2模块配合使
用来访问Internet资源。
代码片段:
的对象。
整个cookie都存储在内存中, 对Cookie Jar实例进
行垃圾回收后cookie也将丢失, 所有过程都不需要单独去操作
手动添加cookie:
4、伪装成浏览器
某些网站反感爬虫的到访,于是对爬虫一律拒绝请求。
所以用
Forbidden的情况。
对有些header要特别留意, Server端会针对这些header
做检查:
1.User-Agent有些Server或Proxy会检查该值, 用来判
断是否是浏览器发起的Request。
2.Content-Type在使用REST接口时, Server会检查该
5、验证码的处理
对于一些简单的验证码,可以进行简单的识别。
我们只进行过一
些简单的验证码识别,但是有些反人类的验证码,比如12306
,可以通过打码平台进行人工打码,当然这是要付费的。
6、gzip压缩
有没有遇到过某些网页,不论怎么转码都是一团乱码。
哈哈,那
说明你还不知道许多web服务具有发送压缩数据的能力, 这可
以将网络线路上传输的大量数据消减60%以上。
这尤其适用于
XML web服务, 因为XML数据的压缩率可以很高。
但是一般服务器不会为你发送压缩数据,除非你告诉服务器你可
以处理压缩数据。
于是需要这样修改代码:
这是关键:创建Request对象, 添加一个Accept-
encoding头信息告诉服务器你能接受gzip压缩数据。
然后就是解压缩数据:
7、多线程并发抓取
单线程太慢的话,就需要多线程了,这里给个简单的线程池模板
这个程序只是简单地打印了1-10,但是可以看出是并发的。
虽然说Python的多线程很鸡肋, 但是对于爬虫这种网络频繁型
,还是能一定程度提高效率的。
(随机推荐阅读本站500篇优秀文章点击前往:500篇优秀随机文章)