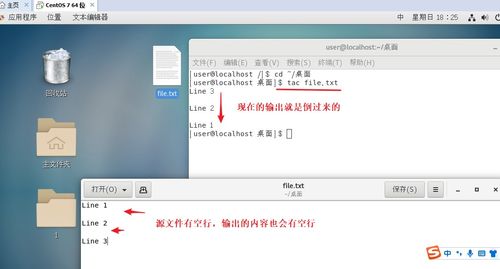
python爬虫代码完整版,python爬虫图片 在目录中存在图片1 跳过该图片1,继续写入图片2的代码
python爬虫代码完整版目录
python爬虫图片 在目录中存在图片1 跳过该图片1,继续写入图片2的代码
python爬虫代码完整版
以下是一个简单的Python爬虫代码完整版示例:。
。
```python。
import requests。
from bs4 import BeautifulSoup。
。
# 发送GET请求获取页面内容。
def get_html(url):。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0;Win64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'}。
response = requests.get(url, headers=headers)。
return response.text。
。
# 解析HTML页面,提取所需数据。
def parse_html(html):。
soup = BeautifulSoup(html, 'html.parser')。
titles = soup.find_all('h3', class_='title')。
links = [title.find('a')['href'] for title in titles]。
return links。
。
# 将数据保存到文件。
def save_data(links):。
with open('results.txt', 'w') as f:。
for link in links:。
f.write(link + '\n')。
。
# 主函数。
def main():。
html = get_html(url)。
links = parse_html(html)。
save_data(links)。
print('爬取完成!')。
。
if __name__ == '__main__':。
main()。
```。
。
。
1. 使用`get_html`函数发送GET请求获取页面内容。。
3. 使用`save_data`函数将数据保存到文件中。。
4. 在`main`函数中调用上述函数,完成爬取并保存数据。。
5. 执行`main`函数。。
。
注意:在实际使用中,爬虫需遵守相关网站的爬取规则,包括但不限于限制访问频率、处理反爬手段等。。
python爬虫图片 在目录中存在图片1 跳过该图片1,继续写入图片2的代码
给你一个代码借鉴下:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import requests
import re
import os
Header = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36"}
def picture_get(picture_url):
try:
root = "E:/pic/"
path = root + url.split(/)[-1]
if not os.path.exists(root): # 目录不存在创建目录
os.mkdir(root)
if not os.path.exists(path): # 文件不存在则下载
r = requests.get(picture_url, headers=Header)
f = open(path, "wb")
f.write(r.content)
f.close()
print("文件下载成功")
else:
print("文件已经存在")
except:
print("获取失败")
求一个python网络爬虫的代码(获得某网页内容)
爬取来说的话,模块有:request、urllib2、pycurl
框架有:scrapy
解析网页有:xpath、美丽的汤、正则、lxml
就接触过这么多
二营长seo
import os,re
def check_flag(flag):
result = True if regex.match(flag) else False
return result
#soup = BeautifulSoup(open(index.html))
from bs4 import BeautifulSoup
html_content =
<a href="">测试01</a>
<a href="">测试02</a>
<a href="">测试01</a>
<a href="">测试01</a>
file = open(rfavour-en.html,r,encoding="UTF-8")
soup = BeautifulSoup(file, html.parser)
for element in soup.find_all(img):
if src in element.attrs:
print(element.attrs[src])
if check_flag(element.attrs[src]):
#if element.attrs[src].find("png"):
element.attrs[src] = "michenxxxxxxxxxxxx" +/+ element.attrs[src]
print("##################################")
with open(index.html, w,encoding="UTF-8") as fp:
fp.write(soup.prettify()) # prettify()的作是将sp美化下,有可读性
(随机推荐阅读本站500篇优秀文章点击前往:500篇优秀随机文章)