Linux统计文件中单词的个数,如何使用linux命令统计文本中某个单词的出现频率
linux中,如何使用awk计算一个文本(只有一行)中有多少个单词呢
linux设计程序计算文件的统计信息:字符数,非空白字符总数和文件中字母总数,并将结果输出到屏幕另一个文件
使用Linux命令行工具可以很容易地统计文件中单词的个数。可以使用以下命令:。
。
```。
$ cat file.txt | wc -w。
```。
。
其中,`cat file.txt`将文件内容输出到标准输出,管道符`|`将输出传递给`wc`命令,`-w`选项告诉`wc`命令仅统计单词数。执行该命令后,将输出文件中单词的个数。"。
linux中,如何使用awk计算一个文本(只有一行)中有多少个单词呢

gawk '{print $1 }' filename |wc -l
这个事把文件每个单词打印一行,然后通过wc进行行计数。
原理简单,可行。
如何使用linux命令统计文本中某个单词的出现频率
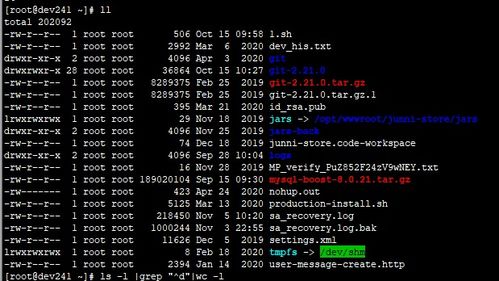
cat /etc/passwd | awk -F ':' 'BEGIN{count=0;search="root";} {for(i=1;i<=NF;i++){if($i==search){count++;}}} END{printf("The word %s is used %d times. ",search,count);}'
我把次数给算出来了,你说的频率如果是100%,你可以适当修改一下就能出来。
我机器上跑出的结果:
The word root is used 2 times.
linux设计程序计算文件的统计信息:字符数,非空白字符总数和文件中字母总数,并将结果输出到屏幕另一个文件
1.写一个程序来计算一门课的成绩(满分100).这门课程的记录包含在一个文件中,该文件将学生的名字,又一个空格,最后是学生10次测验的分数(全部包含在一行中).测验分数全部是整数,而且每个分数都以空格分隔.程序将从这个文件读取输入,并将输出发送到另一个文件.输出文件中的数据与输入文件中的数据几乎一样,唯一的区别在于输出文件中各行末尾多一个double类型的数.这个数是该学生10次测验的平均分.
2.写一个程序,用他纠正c++程序中操作符<>用法错误,这两个操作符与cin和cout配合使用.你的程序将把每个错误的cin<>,cout>>替换成cout<<.一个比较简单的版本是,假定每个cin及其后面的<>之间有且只有一个空格. 3.这个程序用于为一个文本文件中的各行编号.请写一个程序,要求它从一个文件中读取文本,并将读取的每一行同时输出到屏幕和另一个文件,并为其附加一个行号.要在每行的起始处打印行号.行号占3个字符位置的一个域,并在这个域中右对齐.在行号之后,请添加一个冒号,再添加一个空格,最后附上原来的文本.每次都应该读取一个字符,而且要忽略每一行原来在开头位置的任何空格. 4.写一个程序,用它计算一个文件下的一下各项统计信息:文件中的字符总数`,非空白字符的总数和文件中的字母数.并将统计结果输出到屏幕和另一个文件. 做出来的人多谢了~! 绝对有好处z~! (随机推荐阅读本站500篇优秀文章点击前往:500篇优秀随机文章)